
티스토리 뷰
[논문 리뷰] From Big to Small: Multi-Scale Local Planar Guidance for Monocular Depth Estimation
감자보이 2021. 8. 29. 20:55컴퓨터 비전에서 카메라 이미지를 통해 Depth를 추정하는 것은 활발하게 연구되고 있다.
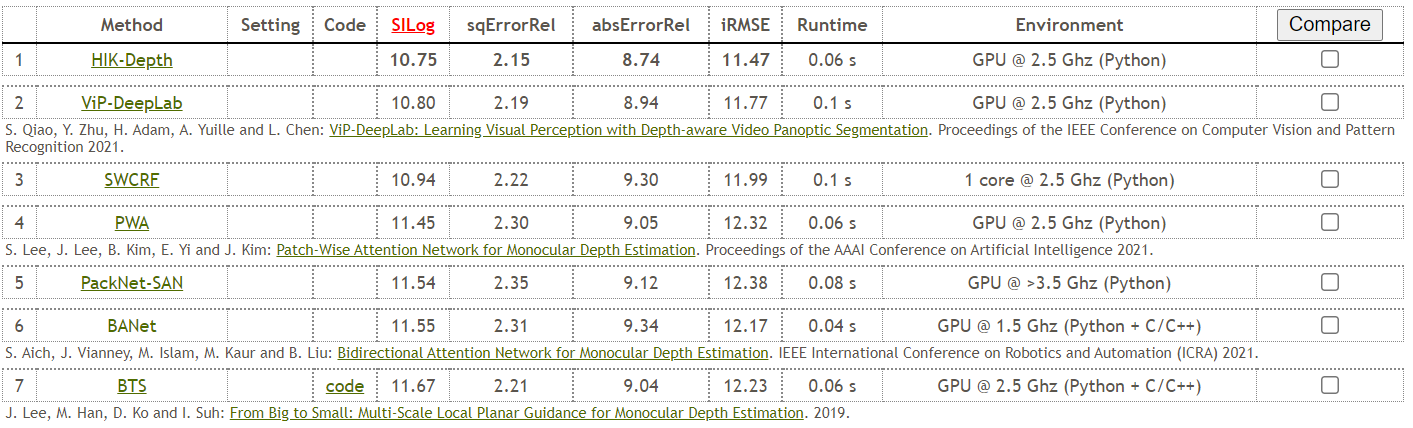
이때, Kitti에서 상위권에 차지하고 있는 논문 중 하나인 일명 BTS 논문에 대해서 리뷰해보려고 한다.
Abstract
최근 single image(단안 이미지)에서 depth를 estimate 하는 문제를 CNN을 이용하면서 성능이 우수해지고 있다. 주로 encoder - decoder 구조를 이용한다.
encoder : 기존 이미지에서 dense한 feature를 뽑는다.
decoder : feature를 이용해 depth를 prediction
encoder - decoder 구조를 효과적으로 사용하기 위해 다양한 기술들을 사용하며(skip connections, multi-layer deconvolutional network 등등), 본 논문에서는 feature를 이용해 효과적으로 depth prediction을 할 수 있도록 decoding 시 novel local planar guidance layer를 추가했다.
1. Introduction
- 고전적인 방식으로는 stereo 이미지 쌍을 이용, 다른 lighting condition에서 찍은 frames, 연속적인 frame을 이용해 depth 추정
- 단일의 이미지로 depth를 추정하는 것은 ill-posed problem(1개의 유일한 정답이 존재하지 않는 ‘불량 조건 문제'
- 인간은 한 이미지로 거리를 판단할때, Local cue(물체에 대한 특징, 상대적인 Scale, 빛의 변화 등등)과 Global Context(전체 Scene에 대한 이해)를 같이 고려
- 본 논문은 supervised learning이며 dense feature extraction을 위한 인코더와 desired prediction을 위한 디코더 구조로 되어있다.
- 인코더에서는 feature를 잘 뽑는 segmentation 기법 이용
- 디코더에서는 Local Planar guidance Layer 제안 decoding 시 각 stage(1/8, 1/4, 1/2)에서 guidance layer를 둔다.
2. Related Work
- Supervised Monocular Depth Estimation
- training 시에 depth에 대한 Ground truth값 필요
- Semi-Supervised Monocular Depth Estimation
- 다른 센서들로 ground truth를 얻어야 하지만 센서 데이터 오차 생길 수 있음
- Self-Supervised Monocular Depth Estimation
- Image Reconstruction 문제로 접근
- depth Map의 정확도 측면에서 최근 Supervised Learning 기법보다 떨어지는 경향이 있다.
- Video-Based Monocular Depth Estimation
- sequential data를 이용해 추정하는 방식
3. Method
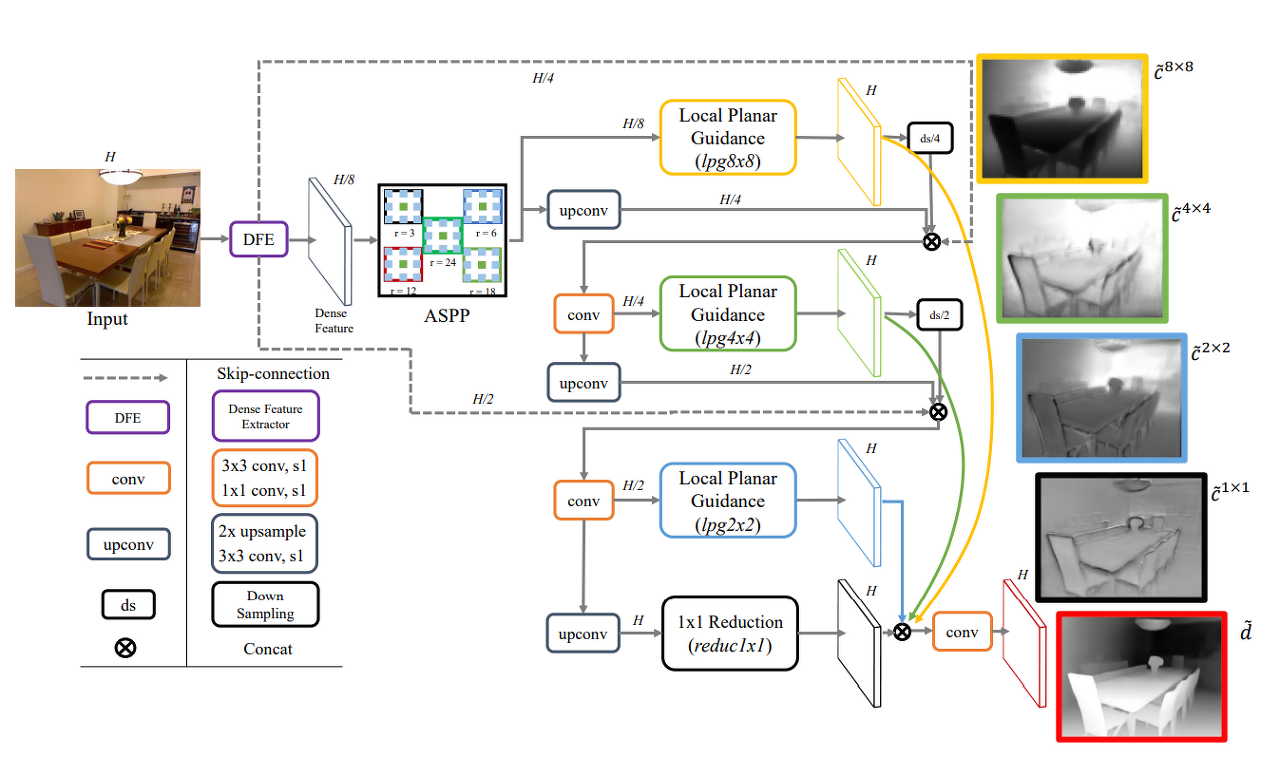
- Network Architecture
- 기존 resolution 크기를 1/8 까지 인코딩(using backbone network) 후 atrous spatial pyramid pooling layer(ASPP)를 거친다.
- ASPP : Atrous convolution은 Receptive field를 넓혀주기 때문에 Segmenation 분야에서 Detail을 살려주기 위한 기법으로 많이 사용된다. Atrous convolution을 여러 Scale에 사용하여 Multi-scale에 잘 대응할 수 있는 Pooling 기법이 ASPP이다. 이때 various dilation rates 사용(3,6,12,18,24)
- 디코딩 시에는 local planar guidance layer(LPG)를 사용
- finest estimation을 위해 1*1 reduction layer 사용
- 마지막으로 concat 후에 conv 후 추정 d 얻을 수 있다.
- Multi-scale Local Planar Guidance

Local Planar Guidance Layer의 구조 - 이 논문의 key idea는 feature와 final output 사이의 직접적이고 명시적인 관계를 효과적으로 맺게 하는 가이드를 제공한 것이다.
- 1,2 channel을 각각 theata와 phi로 사용하게 되며 이를 통해 unit vector를 구상할 수 있게 된다.

theata 와 phi를 이용해 세개의 unit vector 구성 - ray-plane intersection을 이용해 unit vector 와 3차원 상 평면의 관계를 구성해준다. 자세한 건 이 페이지 참고
Intersection of camera ray and 3D plane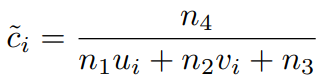
ray-plane intersection을 통해 nonlinear combination 식 구성 - LPG layer을 이용하여 Upsampling을 진행하게 되면 단 4개의 계수(n1, n2, n3, n4)로 reconstruction이 가능해지는데, 일반적인 Upsampling 전략은 k^2 value가 필요한 것에 비해 매우 효과적인 방법이라 할 수 있다.
- 최종 d를 예측하기 위해 단계별로 동일한 공간 위치의 특징을 함께 사용하므로 효율적인 표현을 위해 global shape이 coarser한 scale에서 학습되고 local detail은 finer scale에서 학습될 것으로 기대한다. 또한 서로 상호작용하여 잘못된 추정을 보정할 수 있다.
- Training Loss
- Eigen et al 에서 사용된 loss를 이용해 loss를 재구성한다.

Eigen et al에서 제시한 loss - 식을 자세히 살펴보면 variance와 square mean error의 합으로 이루어져 있는데 variance의 영향을 최소화하기 위해 본 논문에서는 람다를 0.85로 설정했다고 한다.

최종 loss - 최종적으로 loss를 다음과 같이 구성했으며 알파 값은 실험적으로 10으로 지정했다.
- Eigen et al 에서 사용된 loss를 이용해 loss를 재구성한다.
4. Result


결과를 확인해 보면 기존 SOTA 논문들에 비해 윤곽부분에서 정확도가 상당히 높았으며 backbone network는 ResNext-101을 사용했을 때 가장 높은 성능을 내는 것을 확인할 수 있었다.
단안 이미지로 깊이값을 추출하게 되면 활용될 수 있는 분야가 매우 많을 것이라고 판단된다. 하지만 아직까지는 네트워크 자체가 무겁기 때문에 네트워크 경량화 부분에서도 신경을 써야 할 것으로 생각된다.
'연구 일지 > 논문 리뷰' 카테고리의 다른 글
- Total
- Today
- Yesterday
- Camera
- segmentation
- 연구
- 논문리뷰
- 논문
- 자율주행
- opencv
- mobile robot
- path planning
- Visual Odometry
- 딥러닝
- 블로그 #작성요령 #시작
- prediction
- 컴퓨터비전
- slam
- bts
- depth
- 리뷰
- 아르떼뮤지엄 #여수 #여행
- Vision
- 논문구현
- estimation
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |